Bacula backup server on Debian Lenny, with remote SQL server
Contents
- 1 What is Bacula?
- 2 Bacula components
- 3 About this guide
- 4 Package installation on our Director server
- 5 Configuration
- 6 Starting the components
- 7 Tapes/volumes in the Media database / pools from an autochanger
- 8 Run your first job
- 9 Adding a remote linux client
- 10 Adding a remote windows client
- 11 The MySQL server
- 12 Links, references, scratch
This node is a REALLY REALLY incomplete scratch-space for my bacula-related node…
What is Bacula?
First of all, if you are reading this, I hope you have at least a minimal knowledge of what Bacula is. As in, at leas you know that is is a system for backup, recovery and verification of computer data. Hopefully, you also know that it is a scalable, enterprise-ready solution, and you are prepared for that.
As with everything else that gets labeled 'enterprise', and even 'scalable', Bacula is a system that is split into several parts, and is highly configurable. This gives great flexibility, at the cost of being rather complex to set up compared to smaller, simpler systems.
If you are looking to back up your workstation, and only that, bacula is probably not for you. The same is probably true if you are looking at doing backups for a small set of computers; say two-to-four. On the other hand, if you are planning on doing backups for a greater number of systems, across operating systems, and/or require dependable backup volume control, bacula is probably very well suited.
If you are coming from a commercial Enterprise backup solution, you may be surprised (hopefully pleasantly) to see that setup of Schedules, Clients, Jobs and the like are done in text-based configuration files, rather than a point-and-click GUI (or cryptic command line console).
Bacula components
As mentioned, Bacula is split into several parts. The following figure tries to show the central components, with the arrows describing direction of command- and data flow initiation.
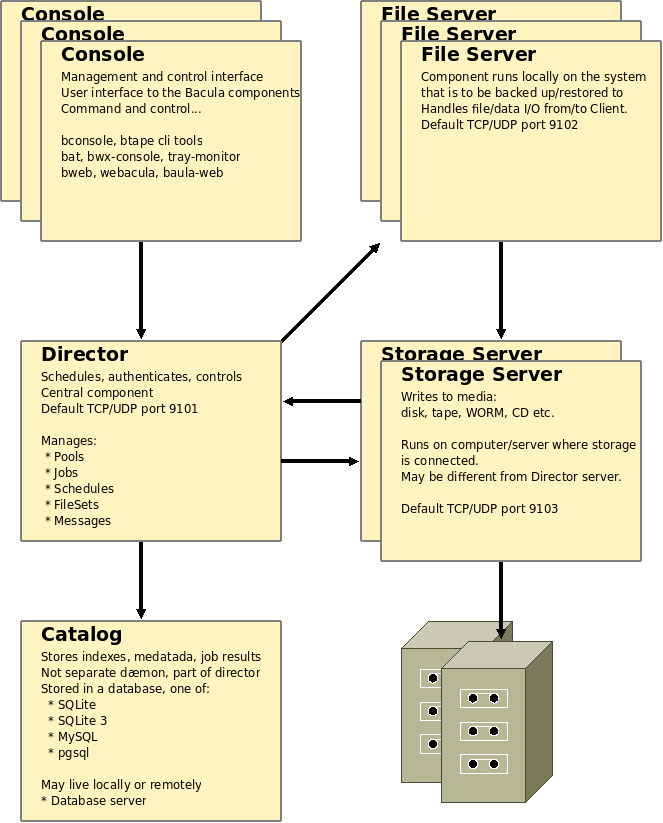
Director
Central to a bacula installation is the Director. Simply put, the Director is the Bacula server itself, the central component that implement scheduled tasks, control running of backups and restores, and handles messages and reporting.
Console
Console applications exist in a variety of flavours for Bacula. Common for them is that they allow administrators to communicate with the Director (and other components via Director) to show status, list information, manipulate storage pools, run jobs et cetera.
Different from many other Enterprise solutions, the management console is only used for managment, reporting and maintenance, and not for configuration. Configuration of Bacula components is done in configuration files, while the Console allows the administrator to operate and manage the dynamic environment that result from 'static' base configuration.
So, as an example, the definition of a Client and a Job definition for the Client is done in configuration files, and the resulting data stored when the Job is run is managed using the Console. Another example may be that a Storage and a Pool gets defined in configurations, whereas manipulation of Volumes assigned to the Pool and Storage will be managed though the Console.
File Server
The Bacula File Server is known also as File Daemon and Client program. This is the software installed on the machine to be backed up. The File Server is responsible for recieving commands from the Director, and sending data for backup to a Storage, or recieving data from a restore. The File Server handles reading and writing data from/to the file systems on the machine, along with file and security attributes associated with the data.
The File Server is not responsible for defining what data to be backed up. This is part of the configuration done at the Director.
Storage
As the name should imply, a Storage Server (or Daemon) handles storage of backup data on storage systems. A singe Storage Server may be used by multiple Directors, and a single Director may use multipe Storage Servers, allowing for a very flexible and scalable solution.
Storage Servers use actual storage directly, either as file-based storage in the filesystems available at the host running it, or as storage devices available at the host. File, tape, WORM, FIFOs and CD/DVD-rom are supported as storage types, and a large variety of autochanger systems are supported, especially for Tape-based storage.
A single Storage Server can serve multiple Storage devices/definitions to the Directors and File Servers communicating with it.
Since Bacula communication with the Storage Server is done using TCP/IP, this component can exist on any host accessible to Director and File Servers, including the same host.
Catalog
The Catalog component is not a separate program in and of it self, but is a central concept. As with all large-scale backup solutions, a large amount of meta- and index-data gets generated by Bacula. Dynamic data generated by an operating Bacula system needs to be stored. Examples may be indexes of files for a backup that has been run, the state of the media pools. Bacula saves this information in the Catalog.
The Catalog gets stored in a relational database, an SQL database. Three different storage backends are available: SQLite, MySQL and PostgreSQL. The database may be stored locally, on the same host as the Director, or it may be stored on a remote database server (mysql/pgsql). In this guid, a remote MySQL server will be used.
About this guide
The goal of this document, is to end up with a system consisting of:
-
One Director server
-
One Catalog for the Director stored in a remote MySQL database
-
One Storage Server running on the same host as the Director
-
Two storage Devices:
-
A File-based storage
-
An autochanger, using mhvtl
-
-
-
Three Clients
-
The localhost / director server
-
A remote Debian system
-
A remote Windows system
-
-
A separation of (at least) Client-related configuration into smaller files.
And since I called this section “About this guide”, this should be the location where I say that I take no responsibility whatsoever for any results you may experience if trying to implement a Bacula system when/after reading this.
Package installation on our Director server
The version of bacula in the standard repositories for Debian Lenny is really old, 2.4.4-1, compared to the latest stable, 5.0.3. I will be using Lennny Backports to get a more recent version, 5.0.2-2…
I chose to go with MySQL in this setup. I would prefer going with pgsql, but as I wanted to focus on bacula, not database administration, I took the “easy way out”, seeing that I am more experienced as a MySQL DBA…
First two basic tools:
apt-get -y install \ libterm-readkey-perl \ psmisc
Next, we'll add Lenny Backports to our APT sources, to be able to get a more recent version of bacula.
echo -e "\n\ndeb http://backports.debian.org/debian-backports lenny-backports main" >> /etc/apt/sources.list apt-get update
I also want future updates to be pulled from backports, to get security fixes and the like. So I added the following to /etc/apt/preferences
Package: * Pin: release a=lenny-backports Pin-Priority: 200
Since I do not want the MySQL server to be installed on the server running Bacula Director, and I want to avoid pulling in too many “unneeded” packages, the option ”–no-install-recommends” is added to the following command. If you prefer to use aptitude, replace this option with ”–without-recommends”. Note that the lenny-backports version of the packages will be pulled in, thanks to the ”-t lenny-backports” option. This option is identical for apt-get and aptitude.
apt-get \ -t lenny-backports \ --no-install-recommends \ install \ bacula-director-mysql \ bacula-console \ bacula-doc bacula-fd \ bacula-sd \ bacula-sd-mysql
I already have a fairly well performing, and maintained database server, and I do not like the concept of “a new DB server for each app”, the setup will be using my already existing database server. Unfortunately, dbconfig-common does not support comnfiguration of remote SQL servers for bacula. So when debconfig asks this:
Configure database for bacula-director-mysql with dbconfig-common?
… the answer is No
This leads to a different problem: The installation “fails”, because the post-install script for bacula-director-mysql fails. This (should) be solved by doing a bit of configuration, and then coming back later to fix this with “apt-get -f install”((I have been notified that the database setup even fails if you are installing mysql-server as a dependency for local database use… This is because the mysql-server is not yet running when debconf tries to use dbconfig-common…)).
Database seeding
Before we can start setting up bacula, we need to set up our database. Because I chose to use a remote SQL server, and dbconfig-common is braindead and does not understand that concept, the database will have to be created and seeded with tables manually.
This is strictly speaking a part of Configuration, but also so important for the elementary setup, that I will call it a part of installation.
Unfortunately, the packages ships only with a shell-script to seed the tables, assuming that the database will be installed locally. Fortunately, the script is basically an SQL script wrapped with shell-commands. So, lets use that!
cp /usr/share/bacula-director/make_mysql_tables ~/bacula_init.sql vim ~/bacula_init.sql
Remove the top lines leading up to, but not including the line:
USE ${db_name};
On that line, replace '${db_name}' with the actual database name that you'll be using. If you, as I, prefer to use InnoDB rather than MyISAM, add the following as the absolute top line of the file:
SET storage_engine=INNODB;
Next, go to the bottom of the file, and remove everything from (including) and below the line:
END-OF-DATA
The lines you remove should be the mentioned one, plus some “then - echo - else -echo - fi - exit” …
So, now that we have a SQL script to use, create the actual database on the database server, and grant fairly open permissions on the database to a user created for bacula. The following is not good practice, but it will get the job done. If you want more precise control, please do so when adding the grant, but also remember that you can easily modify the grant later on….
ssh databaseserver mysql -u root -p mysql
create database bacula_db; grant all privileges on bacula_db.* to 'bacula'@'backupserver' identified by 'password';
Now that the database is created, and a user for bacula is created and granted permissions to use the database, it is time to fill the database. Get back to our bacula server, and load the SQL script.
mysql -h databaseserver -u bacula -p < ~/bacula_init.sql
Configuration
Since Bacula is separated into different components that can live completely separate, configuration of these components are split into respecitve configuration files. Needless to say, these configuration files will relate to each other, enabling communication between the components. Here is an attempt at visualizing the relations:
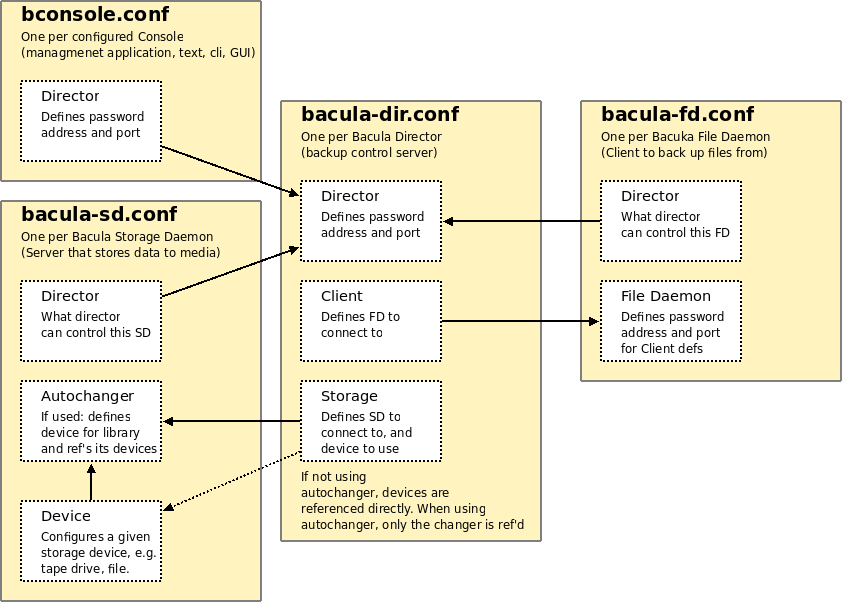
The two most central configuration files, in my “backupserver”-oriented view, is the Storage Daemon config, bacula-sd.conf, and the Director conf, bacula-dir.conf. I started by getting to know the bacula-dir.conf file, and then started working with the configuration by setting up my Storage Daemon, so that I had my storage devices available.
Before we dive into the configuration of Bacula, we should get an overview on what the Director configuration file contains, how it is sectioned, and how the sections relate to each other (and the surrounding world).
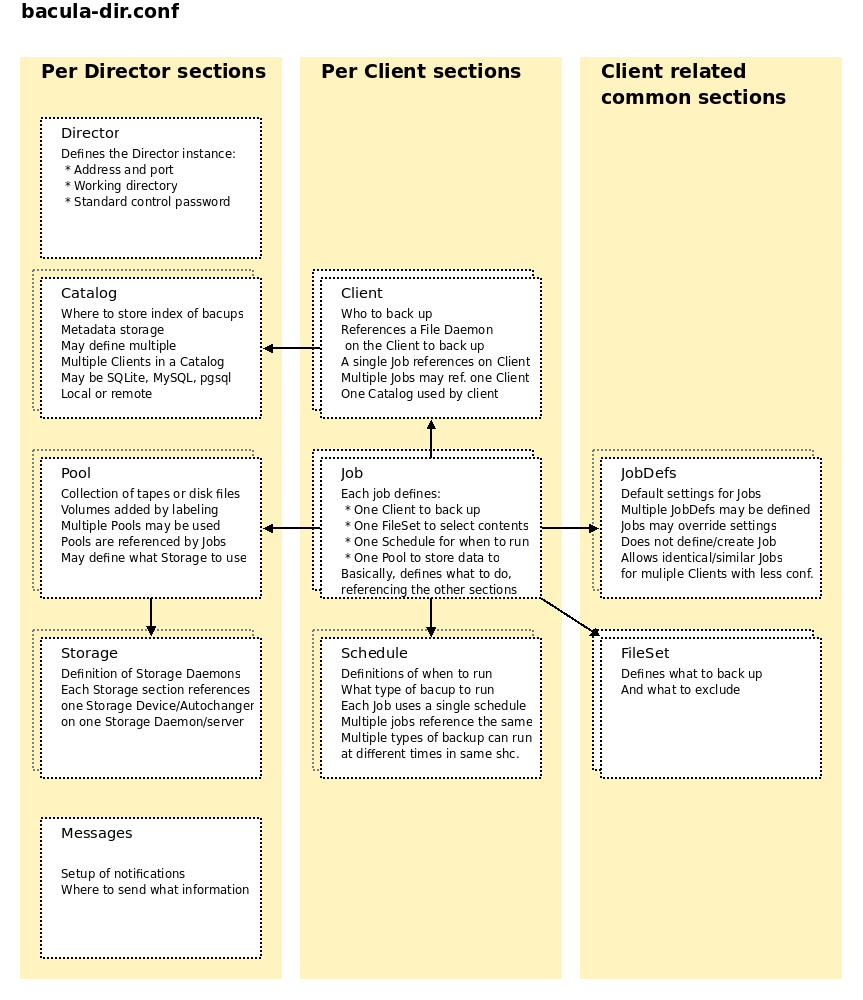
I won't describe the sections in text here, so take some time examining the above figures until you feel you have a grasp on how the files and sections are related.
Note In the following configuration, note the following:
-
The hostname of the server hosting my Director and Storage Daemon is bactank
-
The hostname of my database server is simply database
-
The hostname of my Linux client is linuxclient
-
The hostname of my Windows client is windows
-
I will be using one FileSet for each client
-
On the host bactank I will be excluding /opt completely, and store VTL files and File-based “volumes” under that directory.
NOTE
In the Debian configuration files, the passwords seem like they are auto-generated. They are not. Please generate new passwords wherever appropriate. To be relatively random, you can use pwgen like this:
pwgen -s 32 1 AwAdLG9doWqJuQgZ0BmnMViX8lCgAH7S
Storage Daemon
My goals for the Storage Daemon is, as stated, to run it on the same host as the Director, and to provide two types of Storage though it: a File based storage, and a mhvtl autochanger/virtual tape library. Before progressing, you may want to take a quick look at my mhvtl (TODO: Update link!!) description/guide, to get familiar with how the virtual library is represented as SCSI devices.
A bit of work has been done for us by the Debian packages, so the configuration file for the SD is already prepared for communication from the Director. Most importantly, this means that proper password relationships have been set up.
But, in my opinion, a lot of unneeded stuff is in there as well. I started with the debian-package-file, and stripped away all that I did not want, and added what I needed.
The configuration of the Storage server is /etc/bacula/bacula-sd.conf. It should start with defining the properties of the Storage Daemon it self:
Storage {
Name = bactank-sd;
SDPort = 9103;
WorkingDirectory = "/var/lib/bacula";
Pid Directory = "/var/run/bacula";
Maximum Concurrent Jobs = 20;
}
Here we assign the Storage Daemon a name, and tell it to listen on any interface/address, port 9103. We tell it to use /var/lib/bacula as a scratch/workspace, and finally that we do not want more than 20 concurrent jobs using this Daemon.
Next, we need to set up a definition to allow the Director controlling the Storage:
Director {
Name = bactank-dir;
Password = "random-generated-password-identical-to-director-conf";
}
The Name needs to be identical to the Name that we will assign to our Director instance, and it gets auto-filled by the debian-packages as hostname-dir. The Password will be auto-generated by the Debian-packages, and needs to be identical to the Password = statement in the Storage section of the Director config.
The Debian configuration will also include a Director section for monitoring. Leave this in, I will not comment that part further, than saying that more than one system may control a Storage Daemon, though configured Director sections.
I wanted a File-based backup resource. I will not really use this anywhere, but I an including it to show how to set one up.
Device {
Name = FileStorage;
Media Type = File;
Archive Device = /opt/bacula-filestore;
LabelMedia = yes;
Random Access = Yes;
AutomaticMount = yes;
RemovableMedia = no;
AlwaysOpen = no;
}
No files will be created at this location before bacula actually uses this resource to create a volume and stores data to it. Also, according to my understanding, a new file (volume) will be created for each Job((I have not yet tested File-based storage, so I will probably come back and update this.)). I do not specify any sizes, allowing auto-labelling and Volume Management create and close the files as it sees needed.
Next up, I add the four tape drives presented by mhvtl. I will simply list one of them, as the rest are identical with the exception of the Name and Device:
Device {
Name = Drive-1; # Will be referenced as device name by Autochanger later.
Drive Index = 0 # Index as reported by the changer, and as used by bacula
Media Type = LTO-4; # Description of type of media.
Archive Device = /dev/nst0; # Non-rewinding SCSI device
AutomaticMount = yes; # when device opened, read it
AlwaysOpen = yes; # Keep the device open until explicitly unmounted/released
RemovableMedia = yes; # Well, duh 😉
RandomAccess = no; # Tapes are by nature sequential
AutoChanger = yes; # This device is part of an autochanger
Hardware End of Medium = No; # Needed for proper operation on mhvtl
Fast Forward Space File = No; # Needed for proper operation on mhvtl
# Heed the warnings in the distribution file about tapeinfo and smartctl.
Alert Command = "sh -c 'tapeinfo -f %c |grep TapeAlert|cat'"
}
Note that the Media Type is descriptive, not technology based. Also note that if you have multiple changers with the same media, that do not share the media, you will need to make this different between the changers, or else Bacula may try to load a tape that belongs to one changer, into the other… Adding a pre- or postfix to the Media Type will make them “different” in the Media index, making sure this does not happen.
Since my “autochanger” has four drives, this needs to be repeated for all four of them. When that is done, we get to the Autochanger itself:
Autochanger {
Name = MHVTL;
Changer Device = /dev/sg4;
Device = Drive-1;
Device = Drive-2;
Device = Drive-3;
Device = Drive-4;
Changer Command = "/etc/bacula/scripts/mtx-changer %c %o %S %a %d";
}
Simple enough, this gives the autochanger a name that can be referenced by Director, what “physical” device this is, that Device definitions make up the attached drives of the changer, and finally the command to run for controlling it.
Finally, we define that all messages generated by the Storage Daemon should be sent to the Director for processing/filtering/delivery:
Messages {
Name = Standard;
director = bactank-dir = all;
}
File Daemon for localhost
To be able to flesh out as much as possible of the Director config, I first want to have the File Server/Daemon used to make backups of the backupserver itself defined before starting the Director. So, let's attack /etc/bacula/bacula-fd.conf on bactank.
Here I start out with the definition of the Directors that is permitted to control the client. Just like in the bacula-sd.conf file, there is a Montior definition you can leave in, and focus on the actual Director instead:
Director {
Name = bactank-dir
Password = "random-generated-password-identical-to-director-conf"
}
Again, the Name statement needs to match the Name given to the Director, and it still defaults to hostname-dir. The password will be auto-generated by the Debian packages, and needs to match the Password definition in a relevant Client section of the Director configuration.
Next is the definition of the FileDaemon itself:
FileDaemon {
Name = bactank.example.com; # Name used in Director client config
FDport = 9102; # where we listen for the director
#FDAddress = 127.0.0.1; # If you want to close down to a single address.
WorkingDirectory = /var/lib/bacula; # Where to "scratch and temp"
Pid Directory = /var/run/bacula;
Maximum Concurrent Jobs = 20;
}
The Name can be anything you want, but must be identical in the Directors Client definition, and it will be used for associating data generated from this File Server with metadata in the Catalog. The default will be hostname-fd, but I prefer more verbose naming. Note that the name must differ from the Name statement of your Storage Daemon and your Director, when these run on the same host.
I have commented out the FDAddress statement, telling the FD to listen on any interface. This may be against your security policy, so feel free to lock it down to either the loopback address or a specific IP on the host.
As with the Storage Daemon, we close off bacula-fd.conf with a definition of where to send Messages:
Messages {
Name = Standard
director = bactank-dir = all, !skipped, !restored
}
This is a little more precise than that of the Storage. Here we say that all messages, except thise related to skipped files and restored files, should be sent to the director bactank-dir. In this context, skipped means files not included in the backup because it was configured to be excluded, or skipped because they were not changed when doin incremental or differential backup.
Director
Now we come to the longest configuration file yet, the Director configuration, /etc/bacula/bacula-dir.conf. I could not understand the organization oth the Debian-packaged version, so I have re-organized the file to better reflect the relations of the sections to each other.
Director itself
We start off with the natural top-most section, the definition of the Director itself. As you should have noticed in the above section, consistent Name for the Director is important, it is used not only to identify the Director, but also as a part of the Authentication-Authorization in communication between components.
Director {
Name = bactank-dir;
DIRport = 9101; # where we listen for UA connections
# DirAddress = xxx.yyy.zzzz.www; # IP address to listen on, if needed
QueryFile = "/etc/bacula/scripts/query.sql";
WorkingDirectory = "/var/lib/bacula";
PidDirectory = "/var/run/bacula";
Maximum Concurrent Jobs = 1;
# Console password
Password = "random-generated-password-used-by-console-connections";
Messages = Daemon;
}
If you want the Director to only be available for Console applications on a given IP address, or even only fromlocalhost, use DIRAddress to lock this down.
The Messages directive references a Name given to a Messages section in the same file. We'll get back to this one, but note that this differs from how we wrote Messages sections in the other files. in the other files, the Messages section typically describes what director should recieve what messages. On the Director, we'll be using Messages sections to actually do something with those messages.
A read-only console for monitoring
Console {
Name = bactank-mon
Password = "shared-secret-password-used-in-console-config"
CommandACL = status, .status; # Allow only status-reading.
}
Catalog
The Catalog is so central to the Director, that I put this section next:
Catalog {
Name = StandardCatalog; # One director may have multiple Catalogs.
DB Address = database.example.com; # What server to use, and
DB Port = 3306; # What port to connect to.
dbname = bacula; # The name of the SQL database to use
user = bacula; # The username used when connecting
password = "db_password"; # The password of the database user
}
Hopefully that was relatively self-explanatory. The most common setup, is to use a single Catalog with a single Director. If your setup is LARGE, or you thing you need separate Catalog instanced for some other reason, please reference the official documentation. But before you go: it really is as simple as defining more blocks like the one above.
Messages
Messages are a fairly “used-by-all” element, so I put two sections defining two different behaviours next. First, the message delivery for the Daemon/Director , then the Standard resource that will be used for all other Messages:
Messages {
Name = Daemon;
mailcommand = "/usr/lib/bacula/bsmtp -h localhost -f \"\(Bacula\) \<bacula@bactank.example.com\>\" -s \"Bacula daemon message\" %r"
mail = operator@example.com = all, !skipped
console = all, !skipped, !saved
append = "/var/lib/bacula/log" = all, !skipped
}
Messages {
Name = Standard
mailcommand = "/usr/lib/bacula/bsmtp -h localhost -f \"\(Bacula\) \<bacula@bactank.example.com\>\" -s \"Bacula: %t %e of %c %l\" %r"
operatorcommand = "/usr/lib/bacula/bsmtp -h localhost -f \"\(Bacula\) \<bacula@bactank.example.com\>\" -s \"Bacula: Intervention needed for %j\" %r"
mail = operator@example.com = all, !skipped
operator = operator@example.com = mount
console = all, !skipped, !saved
append = "/var/lib/bacula/log" = all, !skipped
}
Things to note in the above, when compared to the default configuration:
-
I specify a different from-address than the recipient
-
I have changed the recipient to a more sane value
-
I prefer to have the bacula Daemon and Standard log in separate files.
Other than that, the above is fairly stock. Make sure you read the rationale for replacing the from-address in the “NOTE!” block of the default configuration.
Storage
Our Storage servers and devices should follow next.
# Definition of file storage device
Storage {
Name = File; # Name to use when referencing this storage in -dir.conf
Address = bactank; # N.B. Use a fully qualified name here
SDPort = 9103; # Port to listen on. Use SDAddress if you want specific listen.
Password = "random-generated-password-identical-to-sd-conf";
Device = FileStorage;# must be same as Device in Storage daemon
Media Type = File;
}
# Definition of mhvtl autochanger
Storage {
Name = MHVTL; # Name to use when referencing this storage in -dir.conf
Address = bactank; # N.B. Use a fully qualified name here
SDPort = 9103; # Port to listen on. Use SDAddress if you want specific listen.
Password = "random-generated-password-identical-to-sd-conf";
Device = MHVTL; # must be same as Device in Storage daemon
Media Type = LTO-4; # must be same as MediaType in Storage daemon
Autochanger = yes; # enable for autochanger device
}
The comments say “N.B. Use a fully qualified name here”, but in reality, anything that ends up with the IP that the Storage Daemon listens on can be used. Observe that the name used here, will be reported to File Servers, and they will use it to communicate with the Storage Daemon. So all Clients will also need to be able to get an IP from what you enter here:!:
Note that the Storage definition for the autochanger references the Autochanger as Device, not the individual tape drives. It is the responsibility of the Storage Daemon to represent the changer correctly. Also, remember the notes about Media Type when we configured the Storage Daemon.
Pools
A Pool is a collection of media/volumes, and it is natural to define these once we have the Storages defined. Bacula supports a quite “magical” pool; If a pool exists with the name Scratch, Empty and Recyclable volumes of the correct Media Type for a given Job present in this pool will be automatically moved to a Pool that needs additional tapes when Jobs are run. This means we can start by adding all our volumes to the Scratch Pool, and these tapes will be allocated as needed. By also adding the directive “RecyclePool = Scratch”, volumes will be returned to this pool as soon as they get marked as Recyclable and subsequently Purged.
# Default pool definition
Pool {
Name = Default; # The name to reference this Pool
Storage = MHVTL; # A pool uses a singe Storage.
Pool Type = Backup; # Currently supported: Backup..
Recycle = yes; # Bacula can automatically recycle Volumes
AutoPrune = yes # Prune expired volumes
Volume Retention = 4 months # 1/3 year
File Retention = 1 months
Job Retention = 2 months
RecyclePool = Scratch # Move to this pool when markec Recyclable
Cleaning Prefix = CLN # If cleaning tapes are available, they have this pfx.
}
Pool {
Name = Monthly; # The name to reference this Pool
Storage = MHVTL; # A pool uses a singe Storage.
Pool Type = Backup; # Currently supported: Backup..
Recycle = yes; # Bacula can automatically recycle Volumes
AutoPrune = yes # Prune expired volumes
Volume Retention = 24 months # 2 years
File Retention = 9 months
Job Retention = 12 months
RecyclePool = Scratch # Move to this pool when markec Recyclable
Cleaning Prefix = CLN # If cleaning tapes are available, they have this pfx.
}
# Scratch pool definition
Pool {
Name = Scratch
Storage = MHVTL
RecyclePool = Scratch
Pool Type = Backup
}
Volume Retention needs to be set fairly high, at least higher than any File or Job retention. The retention periods define how long data about a given Volume/Job/File is to be kept in the Catalog, and as such, how much time will pass before a Volume Expires…
Please look at the Setting Retention Periods section of the Bacula manual for an explanation.
Schedules
I am a fan of using as few different Schedules in a backup solution as possible. Thus I define the absolutely needed Schedules as early on as possible aswell.
# When to do the backups
# Do a full dump every sunday
# Take a Differential (what changed since last Full) on Wednesdays
# Take increments (what changed since last backup) the rest of the week.
Schedule {
Name = "WeeklyCycle"
Run = Level=Full sun at 2:05
Run = Level=Differential wed at 2:05
Run = Level=Incremental mon-tue at 2:05
Run = Level=Incremental thu-sat at 2:05
}
# In the Monthly Cycle the Pool gets overrided to use the Pool with a
# much longer Volume retention period.
# Every first sunday of the month, make a full backup, then do
# Differential backup on Sunday the rest of the month.
Schedule {
Name = "MonthlyCycle"
Run = Level=Full Pool=Monthly 1st sun at 3:05
Run = Level=Differential Pool=Monthly 2nd-5th sun at 3:05
}
Job Defaults
Creating atleast one JobDefs section, providing generic defaults for Job definitions, makes writing later Job easier, as they then only need to contain the settings specific to that Job, and not repeat a whole lot of config over and over again. If any directive given in a JobDefs section is also given in the Job section, the definition in the Job section naturally replaces the default.
JobDefs {
Name = "DefaultJob"
Type = Backup
FileSet = "Full Set"
Schedule = "WeeklyCycle"
Messages = Standard
Pool = Default
Priority = 10
Rerun Failed Levels = yes
}
This sets up a “template”, where any job using this definition will get:
-
A job type of Backup (other types are: Resore, Verify, Admin)
-
Uses the “Full Set” FileSet definition (will be described later)
-
Runs according to the “WeeklySchedule” described above.
-
Uses the Standard message-handler.
-
Uses media from the pool named Default.
-
Has a Priority of 10 (Higher values means jobs will run later)
-
Will Upgrade the next job to the Type of a job that prevoiusly failed.
FileSet
I add generic FileSets in the common configuration, before Clients and Jobs, simply because they are meant to be just that: generic. If I need to specify what and how to do the files of a given Client or Job more precicely, I put that specific definition along with the Client and/or Job definition.
Here, I'll list my sort-of generic Unix-related FileSet that will try it's best at doing a backup of a complete Unix filesystem, as long as the Client using this in a Job has all files in a single partition.
FileSet {
Name = "Full Set"
# Note: / backs up everything on the root partition.
# if you have other partitons such as /usr or /home
# you will probably want to add them too.
Include {
Options {
signature = MD5
}
File = /
File = /boot
}
Exclude {
File = /proc
File = /tmp
File = /sys
File = /dev
File = /.journal
File = /.fsck
# I typically define /var/lib/bacula as the
# WorkingDirectory for the File Daemon.
File = /var/lib/bacula
# For mysql servers, it is better to dump and restore
# and/or do binlog replay. So, instead of dumping the
# MySQL data directory, do dull database dumps to
# a different location, and use binlogs in addition if
# real incremental MySQL backups are needed/wanted.
File = /var/lib/mysql
# Excluding files/directories that do not exist
# has no effect other than making the FileSet generic..
File = /opt/vtl
File = /opt/bacula-filestore
}
}
FileSets can be buildt VERY complex, this is an attempt at a fairly manageable base-definition. For more details, and more complex examples, look at the relatively long sections in the Bacula Director manual
Client and Job in bacula-dir.conf
Now we actually have a very-close-to useful configuration. The only parts missing are Clients and Jobs. If you remember from far up in the document, One Job may only reference One Client, so even though there is a One-to-Many relationship between Clients and Jobs (one Client may have multiple Jobs associated) each Job is directly tied to one, and only one, Client.
This means that grouping Client definitions and Job definitions together is very natural. So natural in fact, that I'll use file-inclusion features in Bacula configrations to create a separate configuration file for each client.
But, there is one Client, with its associated Jobs, that is natural to include in the bacula-dir.conf file, and that is the Client definition for the bacula server, or localhost if you wish.
Remember from the bacula-fd.conf that we set up, I used the Name bactank.example.com, and used the random-generated Password directive. Using those two strings:
# Client (File Services) to backup
Client {
Name = bactank.example.com;
Address = bactank;
FDPort = 9102;
Catalog = StandardCatalog;
Password = "random-generated-password-identical-to-fd-conf";
AutoPrune = yes; # Prune expired Jobs/Files
}
Now, we'll add the absoutely basic Job for this Client: a full backup.
Job {
Name = "bactank.example.com Default"
JobDefs = "DefaultJob";
Client = bactank.example.com;
Write Bootstrap = "/var/lib/bacula/bactank.bsr";
}
As this uses the DefaultJob JobDef/template, this will use the Full Set standard for Unixes as its FileSet, it will run using the WeeklySchedule, backing up data to the Default pool, and reporting messages to theStandard message facility.
[[[FIX ME]]] Needs a FileSet and Job definition for dumping the Catalog, and backing that up.
One common Job
We'll add one Job that gets tied to the first Client, but will in actuallity be modified in the Console applications when it gets run. This Job definition is the RestoreFiles job. Because all jobs must be defined before they can be used, and all Jobs must be tied to a Client, this gets put in the global config.
But, this Job will (should) never be run as-is. This job exists as a template to be used when starting a restore job. In the console, You'll modify each and every spec in this Job, to match the Restore that will be done.
Job {
Name = "RestoreFiles"
Pool = Default
Type = Restore
Client=bactank.example.com
FileSet="Full Set"
Messages = Standard
Where = /nonexistant/path/to/file/archive/dir/bacula-restores
}
Console
There is one more configuration file to take a look at, before we are done with the basic configuration, and that is the configuration of the Bacula Console locally on the Director server.
This file is named /etc/bacula/bconsole.conf and is very simple:
Director {
Name = localhost-dir;
DIRport = 9101;
address = localhost;
Password = "random-generated-password-from-director-section-in-dir-conf";
}
Starting the components
What order you start the components in should be absolutely irrelevant, because the individual Components will not try to communicate before they need to. E.g. the Director will not contact the SD before a Storage operation needs to be done, or a FD before a Job needs to communicate with the Client.
But to be on the safe side:
/etc/init.d/bacula-sd start /etc/init.d/bacula-fd start /etc/init.d/bacula-director start
Tapes/volumes in the Media database / pools from an autochanger
To get some Tape Volumes to work with, we start by doing a load-and read query to the autochanger, to initialize and inventory the changer.
Start the Bacula console on the Director server host
bconsole
Run the update/inventory:
update slots storage=MHVTL drive=0 scan
The update slots command will output a whole bunch of “Read error” errormessages. This is normal, the VTL simulates an unlabeled/uninitialized tape, and that is what we want when running this command against a fresh VTL.
So, now that we are sure that we have a correctly initialized library with a fresh inventory,
To be sure everything is fresh, and note the slots that we want to add to our Media index, the next step becomes:
status slots storage=MHVTL drive=0
As long as none of the Slots come up with an assigned Pool (or status/media for that matter), we can safely Label the Volumes. To automatically Label Volumes using their “barcode”, use:
label storage=MHVTL drive=0 pool=Scratch slots=1-22 barcodes
Notice that this adds the Volumes to the Scratch pool, where they will reside until they are needed.
Run your first job
Start bconsole (if you exited it earlier)
bconsole
Do the absolutely simplest run command possible:
run
This will show you a list of availabe Job Resources to run. If you haven't added anything beyond my example here, you'll get something like:
A job name must be specified.
The defined Job resources are:
1: bactank.example.com Default
2: RestoreFiles
Select Job resource (1-2): 1
I selected the first resource, as I want to run the first backup. Doin a restore at this point makes no sense 😉
Now, this will list the settings for the job. I'll simply show how I modified the setings from an Incremental to a Full job:
Run Backup job
JobName: bactank.example.com Default
Level: Incremental
Client: bactank.example.com
FileSet: Full Set
Pool: Default (From Job resource)
Storage: MHVTL (From Pool resource)
When: 2010-10-31 23:53:48
Priority: 10
OK to run? (yes/mod/no): mod
Parameters to modify:
1: Level
2: Storage
3: Job
4: FileSet
5: Client
6: When
7: Priority
8: Pool
9: Plugin Options
Select parameter to modify (1-9): 1
Levels:
1: Full
2: Incremental
3: Differential
4: Since
5: VirtualFull
Select level (1-5): 1
Run Backup job
JobName: bactank.example.com Default
Level: Full
Client: bactank.example.com
FileSet: Full Set
Pool: Default (From Job resource)
Storage: MHVTL (From Pool resource)
When: 2010-10-31 23:53:48
Priority: 10
OK to run? (yes/mod/no): yes
Job queued. JobId=1
We can now see that it is indeed running:
list jobs
+-------+--------------------------------+---------------------+------+-------+----------+----------+-----------+ | JobId | Name | StartTime | Type | Level | JobFiles | JobBytes | JobStatus | +-------+--------------------------------+---------------------+------+-------+----------+----------+-----------+ | 1 | bactank.example.com Default | 2010-10-31 23:58:22 | B | F | 0 | 0 | R | +-------+--------------------------------+---------------------+------+-------+----------+----------+-----------+
In this first dump, I simply assumed that communication worked, and that I would have enough storage space for the backup. In a more proper scenario, you should have used the command estimate:
estimate job="bactank.example.com Default"
Using Catalog "StandardCatalog" Connecting to Client bactank.example.com at bactank:9102 2000 OK estimate files=41,763 bytes=855,995,113
I knew that I had set MHVTL up to use tape-files of 15GB size, and that I had 390GB available on the LVM-volume where this gets stored, so handling ~850MB of data would be no problem. I also added Compression to the mhvtl setup, so the resulting storage use was:
bactank:~# ls -lh /opt/vtl/TAPE01L4 -rw-rw---- 1 vtl vtl 512M 2010-11-01 00:01 /opt/vtl/TAPE01L4
So, 850MB got compressed down to 512MB. I could push this way further down, I have used compression level 1 of 9 in my MHVTL configuration.
Adding a remote linux client
Configuration and control of bacula clients / File Servers are done at the Director. But before we configure the Director, we'll start by installing the software.
On the client
What we need to do at the client, is installing and configuring the Bacula File Daemon. On a Debian system, we pull the package in using apt-get((Notice that I skipped setting up lenny-backports. A higher-level director is compatible with an older file daemon)).
sudo apt-get -y install bacula-fd
Next, set up the /etc/bacula/bacula-fd.conf file on the Client host:
Director {
Name = bactank-dir
Password = "random-password-to-use-in-director-client-def"
}
# "Global" File daemon configuration specifications
FileDaemon { # this is me
Name = linuxclient.example.com;
FDport = 9102 # where we listen for the director
WorkingDirectory = /var/lib/bacula
Pid Directory = /var/run/bacula
Maximum Concurrent Jobs = 20
}
# Send all messages except skipped files back to Director
Messages {
Name = Standard
Director = bactank-dir = all, !skipped, !restored
}
Remember to update the Director = references to the name of your Director!
On the Director
Now, we will start using a wee bit of Bacula configuration file magic! We want to keep the main Director configuration as clean as possible. This may in part be achieved by splitting individual client definitions (Client, Job and possibly FileSet) out into separate perr-client files. Bacula configurations support inclusion of external files, and even inclusion of configuration generated by commands!
Since Bacula 2.2.0 you can include the output of a command within a configuration file with the ”@|” syntax. We use this to create a “dot-dee” directory for client configurations. Added to the bottom of the /etc/bacula/bacula-dir.conf on the Director server:
# Include subfiles associated with configuration of clients.
# They define the bulk of the Clients, Jobs, and FileSets.
# Remember to "reload" the Director after adding a client file.
#
@|"sh -c 'for f in /etc/bacula/clients.d/*.conf ; do echo @${f} ; done'"
The reason we have not added this yet, is because loading the configuration will fail if the directory is empty or non-existant.
Before we reload the configuration, we want to add the client in. I prefer to use client-hostname based file-names, so I create the file
/etc/bacula/clients.d/linuxclient.example.com.conf:
Client {
Name = linuxclient.example.com;
Address = linuxclient.example.com;
FDPort = 9102;
Catalog = StandardCatalog;
Password = "random-password-to-use-in-director-client-def";
AutoPrune = yes; # Prune expired Jobs/Files
}
# The full backup for this client.
Job {
Name = "linuxclient.example.com Default"
JobDefs = "DefaultJob";
Client = linuxclient.example.com;
Write Bootstrap = "/var/lib/bacula/bactank.bsr";
}
More or less identical to the first Client, the “localhost” definition…
With that configuration bit in place, we are ready to load up the configuration, and use it. On a bacula console controlling the director:
reload list clients
Automatically selected Catalog: StandardCatalog Using Catalog "StandardCatalog" +----------+------------------------+---------------+--------------+ | ClientId | Name | FileRetention | JobRetention | +----------+------------------------+---------------+--------------+ | 1 | bactank.example.com | 5,184,000 | 15,552,000 | | 2 | web.example.com | 0 | 0 | +----------+------------------------+---------------+--------------+
Adding a remote windows client
Setup of a Windows Client starts out by downloading the appropriate installer from the Win32_64 section ofhttp://bacula.org/en/?page=downloads
When you run the installer, you can choose to install the Client, Consoles, Documentation and any combination thereof. Naturally, since we want to take backups of our Windows system, make sure Client is checked.
If you chose to also install Consoles (bconsole/bat), you will be prompted for Director configuration for the console.
You will not be prompted for information about the File Service, however!
After installation, an example Client definition for your system will be placed at the root of your C: drive. There is not much in that file that you could not have figured out on your own by now 🙂
You will, however, want to have a look at the bacula-fd.conf file. The easiest way to get at that file, is to open your Start meny, locate the Bacula program group, where you'll find Configuration / Edit Client Configuration. Choosing this will open the conf file using Wordpad/Write.
FileDaemon { # this is me
Name = windows.example.com
FDport = 9102 # where we listen for the director
WorkingDirectory = "C:\\Program Files\\Bacula\\working"
Pid Directory = "C:\\Program Files\\Bacula\\working"
# Plugin Directory = "C:\\Program Files\\Bacula\\plugins"
Maximum Concurrent Jobs = 10
}
# List Directors who are permitted to contact this File daemon
Director {
Name = bactank-dir
Password = "random-generated-string-replace-this"
}
# Restricted Director, used by tray-monitor to get the
# status of the file daemon
# This is a local system tray application on Windows.
Director {
Name = windows.example.com-mon
Password = "random-generated-string"
Monitor = yes
}
# Send all messages except skipped files back to Director
Messages {
Name = Standard
director = bactank-dir = all, !skipped, !restored
}
So, as you probably notice, absolutely nothing really magical about that. The most magical-looking may be the Windows specific path-specifications, and the hint “Plugin Directory”. All Client platforms support the concept of Plugins, but perhaps the platform where this is most relevant to mention is Windows. Simply because a lot of Windows servers out there exist to run Microsoft Exchange. Bacula has a plugin that handles Exchange way better than just doing file-level dumps. The plugin is shipped in the Win32/Win64 installer package, so if you are interested in this functionality, read up on the relevant Bacula New Features section.
We move on to adding the client to the Director, by adding the file/etc/bacula/clients.d/windows.example.com.conf. First, we put in the Client definition:
Client {
Name = windows.example.com;
Address = windows.example.com;
FDPort = 9102;
Catalog = StandardCatalog;
Password = "random-generated-string-replace-this";
AutoPrune = yes; # Prune expired Jobs/Files
}
Nothing new here either, a simple Client definition like the ones we have seen before. The FileSet, however, is going to be a lot different. I have only one Windows system that I want backups of, so I put my windows-specific FileSet in the clients.d/client-name.conf file. If you have multiple Windows computers that you want to do, with the same requirements for the FileSet, you should put it in the global Director file instead.
FileSet {
Name = "Windows Full";
# With Portable = no, a Windows backup will only be possible to
# restore on WinNT4+, but saves and restores full NTFS ACL's
Include {
Options {
Signature = MD5
# Windows has no concept of sane case handling in filenames 😉
IgnoreCase = yes
# Setting Portable to No means this backup cannot be restored to
# any operating system other than the Windows NT family (WinNT/XP/2K3/2K8),
# but it also means that VSS can be used and that NTFS ACL will be
# backed up and restored correctly.
Portable = no;
Checkfilechanges=yes
# The 'Exclude = yes' statement means that any WildFile,
# WildDir, File or other path spec will be excluded from
# the paths defined in _this_ include section.
# Exclude is used in the Options part of the Include section
# because we want to use wildcards...
Exclude = yes;
# Exclude Mozilla-based programs' file caches
WildDir = "[A-Z]:/Documents and Settings/*/Application Data/*/Profiles/*/*/Cache"
WildDir = "[A-Z]:/Documents and Settings/*/Application Data/*/Profiles/*/*/Cache.Trash"
# Exclude user's registry files - they're always in use anyway.
WildFile = "[A-Z]:/Documents and Settings/*/Local Settings/Application Data/Microsoft/Windows/usrclass.*"
WildFile = "[A-Z]:/Documents and Settings/*/ntuser.*"
# Exclude directories full of lots and lots of useless little per-user files
WildDir = "[A-Z]:/Documents and Settings/*/Cookies"
WildDir = "[A-Z]:/Documents and Settings/*/Recent"
WildDir = "[A-Z]:/Documents and Settings/*/My Documents/Downloads"
WildDir = "[A-Z]:/Documents and Settings/*/Local Settings/History"
WildDir = "[A-Z]:/Documents and Settings/*/Local Settings/Temp"
WildDir = "[A-Z]:/Documents and Settings/*/Local Settings/Temporary Internet Files"
# These are always open and unable to be backed up
WildFile = "[A-Z]:/Documents and Settings/All Users/Application Data/Microsoft/Network/Downloader/qmgr[01].dat"
# Some random bits of Windows we want to ignore
WildFile = "[A-Z]:/windows/security/logs/scepol.log"
WildDir = "[A-Z]:/windows/system32/config"
WildDir = "[A-Z]:/windows/msdownld.tmp"
WildDir = "[A-Z]:/windows/Download*"
WildDir = "[A-Z]:/windows/Internet Logs"
WildDir = "[A-Z]:/windows/$Nt*Uninstall*"
WildDir = "[A-Z]:/windows/sysvol"
WildDir = "[A-Z]:/windows/KB*.log"
# Temporary directories & files
WildDir = "[A-Z]:/windows/Temp"
WildDir = "[A-Z]:/temp"
WildFile = "*.tmp"
WildDir = "[A-Z]:/tmp"
# Recycle bins
WildDir = "[A-Z]:/RECYCLER"
# Swap files
WildFile = "[A-Z]:/pagefile.sys"
# bacula-fd > 3.0 on win32/64 should be able to use VSS,
# so we want to avoid copying the VSS metadata during the backup
File = "\"C:/System Volume Information\""
# Bacula working directory
WildFile = "C:/Program Files/Bacula/working/*"
}
# Include at least the most common root drive
# Note that all drives must be specified separately,
# just like different filesystems on Unix.
# Also note that bacula expects the Unix directory separator, /
File = "C:/"
}
}
That ought to have a lot of self-documentation. In this FileSet you also see the use of Wildcard-definitions. A WildDir is a wildcard for a directory whose content are to be included/excluded, a WildFile names precicely that, a wildcard for files. Note that Windows FileSets use the Unix directory separator.
Finally, we add the Job for this client:
# The full backup for this client.
Job {
Name = "windows.example.com Default"
FileSet = "Windows Full"
JobDefs = "DefaultJob";
Client = windows.example.com;
Write Bootstrap = "/var/lib/bacula/bactank.bsr";
}
A word of caution. My Windows client normally runs F-Secure antivirus. With its realtime scanner active, my backups were crazy slow (<600kbit/sec) making my backups take forever. Disabling the scanner boosted the speed up to normal speeds. I am investigating ways to either “white-list” the bacula-fd process from the scanner, or temporarily disabling it during backups.
Use a bconsole to reload the configuration, and test it by running an estimate. And that is all there is to it. Windows-clients are really not that different from Unix clients 🙂
The MySQL server
As my Catalog is stored on a remote MySQL server, the parts concering the Catalog dumps in the default configuration files shipped with the Debian packages make little sense. Why pull the data across the wire to the Director server for backup, when the database server needs to be backed up anyway?
The backup of the database server will introduce another important, and useful, feature of Bacula backups. Pre- and post backup commands. Basically, to create a backup of the MySQL server and its databases, we want to do some database maintenance and dumping, and then back up the files on the server.
A pre-script is a command that will be started on the client that is to be backed up, before any file evaluation is done. If the script fails (returns non-zero), the backup will fail. A post-script may similarly be used to clean up after backups.
So, I'll be using a pre-script to dump databases before running the actual backup. But, I'm using a mixed method for dumping. I'm using MySQL's binary logging, allowing atomic change-sets and restores, and backing those up on Increments. On Full and Differential backups, I flush the bin-log, and do a full backup of the databases.
First, a note on my mysql binary logging setup. I have created a separate directory for the binary logs:
mkdir -p /var/lib/mysql_binlog chown mysql.mysql /var/lib/mysql_binlog
The binary log also needs to be configured, by default there is no binary logging enabled on Debian installatoions. So in the [mysqld] section of /etc/mysql/my.cnf, I have the followin lines:
log_bin = /var/lib/mysql_binlog/database log_bin_index = /var/lib/mysql_binlog/index expire_logs_days = 10 max_binlog_size = 500M
So, with binary logging available on the MySQL server, it is time to present the script that will be run on the client before data-transfer. This script is written so it contains the MySQL root password, so make sure you place it safe, and set applicable permissions on it. Alternatively, remove any password (and related command options) from the file, and set up a suitable my.cnf instead.
#!/bin/sh
# Filename: /etc/bacula/scripts/mysqldump.sh
# Based on a mix of MySQL recommendations, example scripts in the
# Bacula Wiki and personal experience.
#
# This script is not provided with ANY warranty.
# It is provided as an example, by Jon Langseth (fishy at defcon dot no)
# and is supplied as-is to the public domain.
# Just a security measure...
cd /tmp
# The backup level is supplied as an argument to the script..
LEVEL=$1
# Bail out if no Level is given...
if [ "${LEVEL}" == "" ];
then
echo "No backup level given. Supply Full, Differential or Incremental"
exit 1;
fi
# Directory to store backups in
DST=/var/local/backup
# A regex, passed to egrep -v, for which databases to ignore
IGNREG='^snort$'
# The MySQL username and password
DBUSER=root
DBPASS=databaserootpassword
# Any backups older than KEEPDAYS will be deleted first
# Cleanup is only done on Full or Differential backups
KEEPDAYS=14
if [ "${LEVEL}" == "Full" -o "${LEVEL}" == "Differential" ]
then
echo "Full/Differential"
# Clean up in the destination directory, to avoid clogging the filesystem
find ${DST} -type f -mtime +${KEEPDAYS} -exec rm -f {} \;
rmdir $DST/* 2>/dev/null
# Create a new directory for the dump, in a DTG-format.
DATE=$(date +%Y-%m-%d-%H%M%S)
mkdir -p ${DST}/${DATE}
# Use the 'show databases;' command using mysql in silent mode
# to get the names of all databases on the server. Iterate
# over all the databases with a simple for-loop.
# WARNING: This, and the later dump, may choke on "esoteric" database names.
for db in $(echo 'show databases;' | mysql -s -u ${DBUSER} -p${DBPASS} | egrep -v ${IGNREG}) ; do
echo -n "Backing up ${db}... "
# Dump the databases individually, flushing all logs in the process.
mysqldump \
--single-transaction \
--add-drop-table \
--add-drop-database \
--add-locks \
--allow-keywords \
--complete-insert \
--create-options \
--flush-logs \
--master-data=2 \
--delete-master-logs \
--user=${DBUSER} \
--password=${DBPASS} \
--databases $db | gzip -c > ${DST}/${DATE}/${db}.txt.gz
echo "Done."
done
else
echo "Incremental"
# Simply flush the binary logs. An incremental restore can then
# be performed by replaying the log files.
mysqladmin --user=${DBUSER} --password=${DBPASS} flush-logs
fi
# Exit cleanly.
exit 0
So, binary logging is enabled on the MySQL server, and the backup script in place, install the bacula-fd package on the database server, and start setting up a Client definition like usual.
Client {
Name = database.example.com;
Address = database.example.com;
FDPort = 9102;
Catalog = StandardCatalog;
Password = "random-password-for-fd-director";
AutoPrune = yes;
}
What is more interesting, is the one line added to the Job definition:
Job {
Name = "database.example.com Default"
FileSet = "Full Set"
JobDefs = "DefaultJob";
Client = database.example.com;
Client Run Before Job = "/etc/bacula/scripts/mysqldump.sh %l";
Write Bootstrap = "/var/lib/bacula/bactank.bsr";
}
There are several ways to run scripts/programs from the Job definition
-
RunScript A section-definition for scripts to run on the Director
-
Run Before Job Path and arguments to a script to run on the Director before the data-part of the Job is started.
-
Run After Job Path and arguments to a script to run on the Director after the data-part of the Job is done
-
Client Run Before Job Path and arguments to a script to run on the Client before the data-part of the Job is started.
-
Client Run After Job Path and arguments to a script to run on the Client after the data-part of the Job is done
-
Run After Failed Job Path and arguments to a script to run on the Director after a Job is detected as Failed.
To these scripts, there are several variables that can be used as arguments with the commands. Most importantly for Client Pre commands:
%% = %
%c = Client's name
%d = Director's name
%i = JobId
%j = Unique Job id
%l = Job Level
%n = Job name
%s = Since time
%t = Job type (Backup, ...)
As seen in my Job definition, after running the Client-Run-Before script, the rest of the Job is simply doing a file-based backup.
If you remember the “Full Set” FileSet, I have Excluded /var/lib/mysql from the FileSet. This means that for a full Restore of this database server, I will have to start the Restore by pulling in the last Full, then merging inn a Differential if that has run after the Full. After that, I will have to reinstall the MySQL server, tank in the SQL files from/var/local/backups. Finally, to get the database up to the latest increment, I'll have to replay all needed log-files.
Documentation related to the pre- and post-scripts are located in the Job definition documentation